智能车实验室在2022年机器人领域的顶级会议IEEE International Conference on Robotics and Automation(ICRA2022)的五篇投稿全部录用,五篇稿件的第一作者分别是李亮、赵恒旺、房素素、武浩然和杨晓潇。其中李亮的论文同时被机器人领域顶级期刊IEEE Transactions on Robotics收录,赵恒旺和房素素的论文被IEEE Robotics and Automation Letters期刊收录。
录用文章清单
1. Li L, Yang M. Joint localization based on split covariance intersection on the Lie group[J]. IEEE Transactions on Robotics, 2021, 37(5): 1508-1524.
2. Zhao H, Zhuang H, Wang C, et al. G3DOA: Generalizable 3D Descriptor With Overlap Attention for Point Cloud Registration[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 2541-2548.
3. Fang S, Li H, Yang M. Adaptive Cubature Split Covariance Intersection Filter for Multi-Vehicle Cooperative Localization[J]. IEEE Robotics and Automation Letters, 2021, 7(2): 1158-1165.
4. Wu H, Li Y, Zhuang H, et al. HR-Planner: A Hierarchical Highway Tactical Planner based on Residual Reinforcement Learning[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 7263-7269.
5. Yang X, Qian Y, Zhu H, et al. BAANet: Learning Bi-directional Adaptive Attention Gates for Multispectral Pedestrian Detection[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 2920-2926.
![第一篇:Li L, Yang M. Joint localization based on split covariance intersection on the Lie group[J]. IEEE Transactions on Robotics, 2021, 37(5): 1508-1524.](/__local/A/55/E9/18FB8043CF3DDF5B607235F4B0B_03CF8A01_1A30.png)

➢ 研究背景与意义
数据融合在机器人领域有着广泛的应用,例如SLAM、目标跟踪、机器人控制等。特别是在多机器人系统中,利用绝对定位与机器人之间的相对定位对各个机器人的位置与姿态进行实时估计显得尤为重要。现有联合定位算法主要存在两个问题,第一,没有考虑不同定位信息源之间的数据关联;第二,机器人运动参数在李群空间内,而非欧氏空间,非线性卡尔曼滤波的线性近似会带来误差。因此亟需设计非欧氏空间考虑非独立性信息源的融合算法,使融合定位结果具有一致性,提高定位鲁棒性。
当机器人平台有多种可用于定位的传感器时,例如激光雷达、相机、惯性导航装置、轮速编码器、基于机器人间通信的相对定位等,融合多种传感器的定位结果可提高定位结果的稳定性。现有融合算法视各个定位结果是完全独立的,但实际中不同定位结果可能存在一定的关联性,例如视觉与激光定位可能利用相似的特征,环境的影响(如遮挡)是关联的,以及机器人间相对定位存在关联性。不考虑这种关联性会导致融合结果过度自信(估计的协方差小于实际协方差),进而对融合定位精度造成影响。
➢ 本文工作
针对当前机器人定位结果融合的一致性问题,本文利用微分流形理论,建立了融合问题的状态空间模型。所提出的方法既不假定观测是完全独立的,也不假定其是完全关联的,而是把其分为独立与关联两部分。并且所有的运算都是在李群上。通过该模型既保证了估计的准确性(李群上运算,而非线性化近似),也保证了估计的一致性(观测噪声分为独立与非独立两部分)。独立观测方差可更新为:
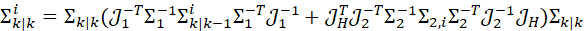
其中 与
与 表示分别表示方差的独立与非独立部分,
表示分别表示方差的独立与非独立部分, 为李群上的雅可比函数。非独立观测方差为
为李群上的雅可比函数。非独立观测方差为 。并且从理论上证明了该算法的一致性,即估计的方差不小于实际方差。
。并且从理论上证明了该算法的一致性,即估计的方差不小于实际方差。
➢ 实验结果
本文对该算法进行了仿真实验与实际多机器人平台的实验,实验结果表明相比于传统滤波方法(如扩展卡尔曼滤波、协方差交集滤波、李群扩展卡尔曼滤波等),在仿真中算法可将定位精度由4m提升到1m,在实际平台(如图1所示)实验中算法可将定位精度提升至7cm以内 (如图2所示)。

图1验证一致性融合方法的定位精度所开发的缩微车系统与实验场地
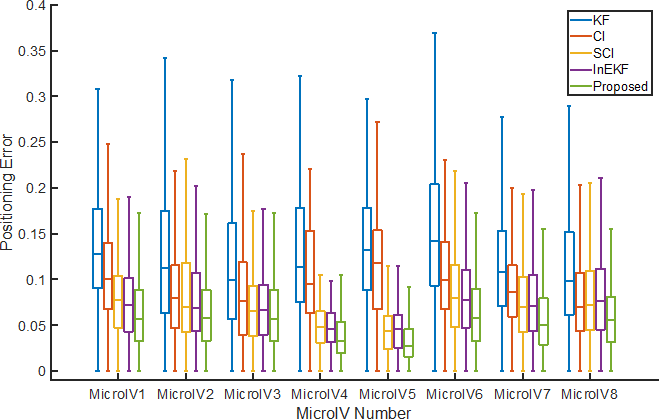
图2 本文所提出的方法与主流定位融合方法对比
[返回]
![第二篇:Zhao H, Zhuang H, Wang C, et al. G3DOA: Generalizable 3D Descriptor With Overlap Attention for Point Cloud Registration[J]. IEEE Robotics and Automation Letters, 2022, 7(2): 2541-2548.](/__local/5/03/9C/ED02293405D6D3C1AB49CA010C6_68746A68_217F.png)

➢ 研究背景与意义
点云配准在机器人、自动驾驶等相关的应用中有重要作用,其中基于三维描述子的点云配准方法,对初始误差具有较高的鲁棒性,有较广的适用范围。早期人工设计的三维描述子虽然能保持旋转不变性,但是其对噪声和遮挡较为敏感。近年来,得益于深度学习强大的特征表达能力,研究者逐渐关注基于学习的三维描述子。现有基于学习的三维描述子,虽然在一些数据集上表现出较好的性能,但是其泛化性能较差,对数据的变化较为敏感,与实际应用还有一定距离。因此,该工作提出一种新的神经网络(G3DOA)来构建三维描述子,该网络同时学习可泛化的旋转不变三维描述子和其空间重叠概率,来提高三维描述子在不同环境中的泛化性能,旨在提升基于学习的三维描述子的泛化性与实用价值,如图1所示。
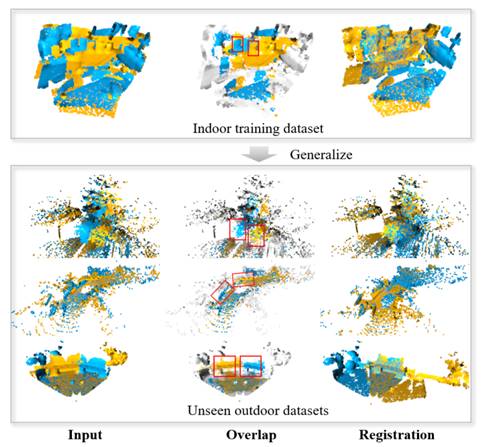
图1 G3DOA仅在室内数据集训练泛化到不同室外数据集的效果展示
➢ 本文工作
该工作提出的G3DOA网络框架如图2所示,它是一种孪生网络架构,使用具有共享权重的两个分支来处理点云对,以源点云(黄色)和目标点云(蓝色)作为输入,经过处理后,输出每个点云采样点的描述子和重叠分数。
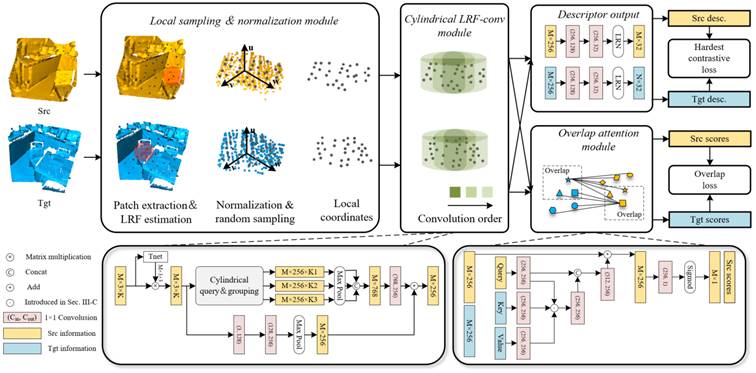
图2 G3DOA网络框架
该网络框架由四个主要模块组成:(1)局部采样和归一化模块将点云转换为旋转不变和尺度不变的表示,并通过随机采样减少点的数量;(2)局部参考系圆柱卷积模块利用多尺度的圆柱形体素和神经网络,学习可泛化且具有区分度的旋转不变特征;(3)重叠区域注意力模块提取两个点云特征编码之间的互上下文信息,并预测每个点的重叠分数,表示该点在两个点云重叠区域概率的大小;(4)描述符输出模块,将特征映射为32维的描述子,并对其进行归一化。
➢ 实验结果
为了验证描述子的泛化性,该工作在一个室内数据集(3DMatch)训练网络,在三个室外数据集(ETH、KITTI和SJTU-Mid100)测试。定性效果如图3所示,第一列为输入的点云对。第二列为使用t-SNE降维的描述子可视化,可以看到在不同的数据集的点云上,对应区域(红框)的颜色相似,非对应区域的颜色是具有区分度的,验证了描述符的泛化性、旋转不变性和可区分性。第三列为估计的重叠区域,其中彩色的点表示位于重叠区域的点,灰色点表示位于非重叠区域的点。第四列为使用描述子进行点云配准后的效果,第五列为真值。

图3 G3DOA在不同数据集的可视化结果
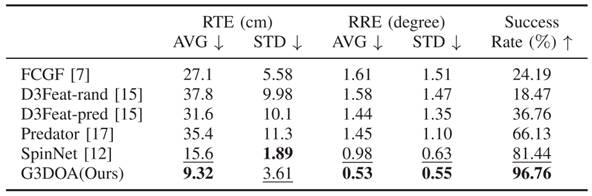
使用室内数据集3DMatch训练的模型,在室外ETH数据集测试的定量结果如表1所示,可以看出G3DOA相比其他方法具有更高的FMR,表现出较好的泛化性。
表1 从3DMatch数据集泛化到ETH数据集的定量结果

使用室内数据集3DMatch训练的模型,在室外KITTI数据集测试的定量结果如表2所示,可以看出使用G3DOA提取的描述子配准的点云,具有更高的精度和成功率,表现出较好的泛化性。
表2 从3DMatch数据集泛化到KITTI数据集的定量结果
该工作在英伟达1080TI GPU上,平均提取每个描述子的时间为2.93毫秒,其中预处理的时间为2.40毫秒,网络推理时间为0.53毫秒,表现出了较好的时间效率,如表3所示。
表3 运行时间分析

[返回]
![第三篇:Fang S, Li H, Yang M. Adaptive Cubature Split Covariance Intersection Filter for Multi-Vehicle Cooperative Localization[J]. IEEE Robotics and Automation Letters, 2021, 7(2): 1158-1165.](/__local/D/D7/4C/0FBF00CB57A0E294F4EE960D125_2A6CC670_2164.png)

➢ 研究背景与意义
目前多车协作定位成为自动驾驶领域一个热点话题,协作定位能够克服单车定位的诸多局限,其可以利用邻车的共享信息来融合多源数据以增强自车定位结果。多车协作定位在实际应用中具有固有的去中心化的实施架构,这使得其可以灵活的处理动态的室外交通环境中的车辆关系,提高容错性能。
然而,这其中有两个关键问题,一个是如何处理多数据融合过程中存在的一些错误类型的数据源,例如非线性情况,动态噪声,相关性问题等。另一个是如何合理的利用邻车共享的额外信息,即车辆间相对位姿估计问题。以往的研究工作一般都聚焦于针对其中一类问题提出相应的方法,或者提出的方法对两类型问题同时存在时效果表现不佳。
➢ 本文工作
这篇文章提出了一种去中心化的基于自适应容积分离协方差交叉滤波算法的协作定位系统,此自适应容积分离协方差交叉滤波算法(ACSCIF)借鉴了分离协方差交叉滤波,容积卡尔曼滤波,以及基于新息的自适应滤波理论,考虑了在状态估计的多数据源融合过程中同时存在的非线性、动态噪声、相关性等错误数据源的情况。同时,本文将先进的点云匹配方法(TEASER++)应用至车辆间相对位姿求解过程中,利用额外的共享信息得到相对定位结果后来增强自车定位。整体架构如下图所示:
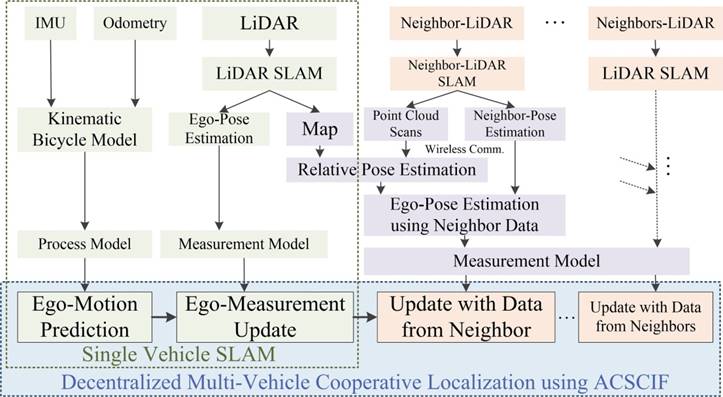
图1 本文提出的基于ACSCIF的去中心化多车协作定位策略
如图所示的协作定位任务中,每辆车执行自己的单车定位任务,同时每辆车与相邻车辆进行交互,通过感知传感器以及车间通讯来使用共享信息,求解得到车间协作相对位姿估计来增强自车定位结果。提出的ACSCIF融合算法通过预测和更新过程融合运动传感器、激光雷达,相对位姿等多源信息,完成递归车辆状态估计。
➢ 实验结果
实验基于CARLA仿真器平台,在不同的噪声环境下(高斯白噪声和有色噪声)设置了两组主要的对比实验,以及实施效率分析。每组实验都对五种方法进行对比,分别是基于扩展卡尔曼滤波的协作定位(EKF-CL)、基于容积卡尔曼滤波的协作定位(CKF-CL)、基于自适应容积卡尔曼滤波的协作定位(ACKF-CL)、基于容积分离协方差交叉滤波的协作定位(CSCIF-CL)以及提出的基于自适应容积分离协方差交叉滤波的协作定位方法(ACSCIF-CL)。选取两种不同的实验场景(常见城市场景和高速路场景)分别进行实验,实验场景如下图所示:
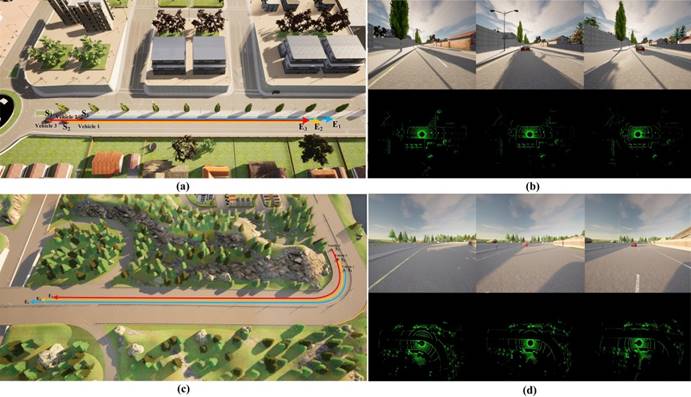
图2 实验路径和场景。(a) 车辆 1(蓝色路径)、车辆 2(橙色路径)、车辆 3(红色路径)在城市公共道路上的测试路径。 (S1、S2、S3为起点,E1、E2、E3分别三辆车的终点。)(b) 车辆1、2、3(从左到右)的(a)所示行驶过程中的视野和对应的点云分布。 (c) 高速公路场景中的测试路径。 (d)车辆在 (c) 所示测试过程中的视野和相应的点云分布。
实验结果使用均方根误差(RMSE)和方差(VAR)来评估各方法的定位精度,下面列举了其中一组实验结果(高斯白噪声环境下的城市道路场景)如下表格所示:

同时,在其他几组不同场景和条件下的实验中,基于ACSCIF的协作定位方法也表现出较好的优势。实验结果表明,本文提出的去中心化的基于自适应容积分离协方差交叉滤波的协作定位策略在不同场景中在定位精度和鲁棒性方面都具有一定的优势。本文也进行了计算效率的分析,通过对各个模块的计算时间和输出频率的分析,可以说明本文提出的去中心化的基于ACSCIF的协作定位系统可以实时运行。
最后,我们可以想象这样一个场景,在路上行驶的几辆汽车中只有一辆具有准确的自车定位能力,而其他所有车辆都失去了准确的绝对定位能力(这种情况的概率很小)。在这种情况下,所提出的策略可以允许车辆融合车间相对位姿和共享局部地图以增强自车定位。本文提出的方法可以确保所有这些车辆几乎始终以最小的成本获得高精度的定位结果,因为具有自车定位能力的车辆的准确定位结果可以以分布式的形式“传播”到其他车辆。此外,该方法可以推广和扩展到状态估计或数据融合的其他领域,如协作建图或增强现实技术,这可能是我们下一步研究的重点。同时,对于一些多车协同任务,未来还可以探索基于优化的方法,如基于图优化方法等。
[返回]
![第四篇:Wu H, Li Y, Zhuang H, et al. HR-Planner: A Hierarchical Highway Tactical Planner based on Residual Reinforcement Learning[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 7263-7269.](/__local/C/AB/05/D187358C37BC06168F3B914B159_84F563B9_2521.png)

➢ 研究背景与意义
该工作围绕高速公路换道决策问题展开。高速公路换道决策关系到车辆行驶的效率与安全性,需要实时地对是否换道、何时换道、是否放弃换道等问题做出决策,为后续运动规划提供依据。换道决策需要与周围车辆博弈以提升自身行驶效率,还需要考虑到安全风险、交通规则以及驾驶舒适性等一系列因素。现实中车辆交互的复杂性和交通参与者行为的不确定性使得该问题难以彻底解决。另外,决策模块依据感知、定位等模块的结果进行决策,这些上游模块在处理数据时不可避免地会产生误差,从而影响决策模块结果的最优性。面对这些问题,基于规则的决策方法需要设计大量规则覆盖各种场景,使得模块臃肿、难以迁移应用,且易受不确定性的影响;数据驱动的决策算法能够以精简的形式从专家数据或仿真交互中学习到人类驾驶水平的策略,但是训练效率低,不如基于规则算法稳定。
|
周围车辆意图未知情况下的决策 |
|
感知具有不确定性和噪声情况下的决策 |
图1 车辆决策中常见难点
近年来,随着第三代人工智能的兴起,知识与数据结合的学习范式受到青睐。数据驱动与基于规则的决策方法相结合,既能够用数据驱动方法强化基于规则的策略,也能够用基于规则的策略提升数据驱动方法的训练效率。
➢ 本文工作
在高速公路换道决策背景下,为了提升在感知和环境都具有较大不确定性的场景中的决策效果,该工作将强化学习与基于规则的策略结合进行换道决策。
主要贡献点主要有:
1. 基于残差强化学习设计了一个层级化变道决策器,用于结合强化学习与基于规则的决策方法。
2. 基于soft constraint 机制改进了一种示教强化学习方法,在强化学习中引入示教数据,以提升训练的效率。
如图2,文章中设计的决策器主要包含两层,其中高层级决策器进行换道决策;低层级决策其进行速度选择,并接受换道决策器的指令。每一层决策器都包含两部分,即数据驱动部分和基于规则部分,并以残差结构相结合。整个决策器输出变道决策和速度选择决策给下游的Frenet 最优轨迹规划器,产生可跟随轨迹。
训练方面,基于强化学习 baseline 算法PPO,并采取了示教强化学习方式。该方法引入了专家数据引导训练过程,通过评估专家策略与当前策略占用度量的差距来限制当前策略的训练过程。随着训练推进,不断放宽限制,从而达到专家数据引导强化学习训练的目的,同时防止次优的专家策略给最终策略引入偏差。训练损失函数具体可表达为

其中,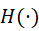 为 Heaviside 函数,
为 Heaviside 函数,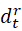 和
和  分别为当前策略与专家策略占用度量差别的估计值、限制阈值。
分别为当前策略与专家策略占用度量差别的估计值、限制阈值。

图2 本文方法框架
该工作强化学习训练采用的奖励值如图3所示。

图3 强化学习训练奖励值
➢ 实验结果
实验基于 CARLA 仿真器进行。采用MOBIL和IDM算法作为方法中基于规则的部分。训练和测试阶段,在仿真器真值中加入噪声以模拟现实中不完美的感知;并给周围车辆添加一系列随机行为来增大环境的不确定性,产生更多边缘场景。
通过文中所提出的方法训练得到的决策器,在不同程度的感知噪声下平均单步奖励值、碰撞率和平均行驶速度如图4。对比baseline方法(MOBIL+IDM),所提出的方法能够在密集的边缘场景中保持更好的行驶安全性,同时尽可能小地影响行驶效率。这表明通过强化学习训练显著提升了基于规则算法在感知和环境不确定性情况下的策略。
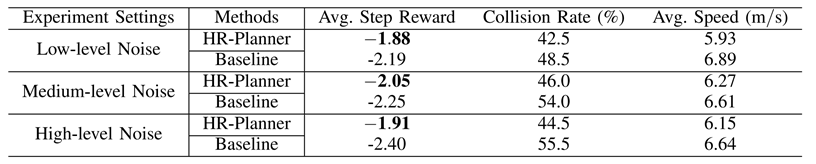
图4 方法测试结果
图5分别展示了文中提出方法在3个场景下的表现效果。图5(a)中,自车决策模块发出换道指令并以获取更快的行驶效率。图5(b)中,面对前方车辆急停,自车决策模块能够及时避让。图5(c)(d)中,决策模块产生变道指令以更高效地行驶,但是当感知到前车也在向相同方向变道时,能够及时放弃换道以保持安全行驶。
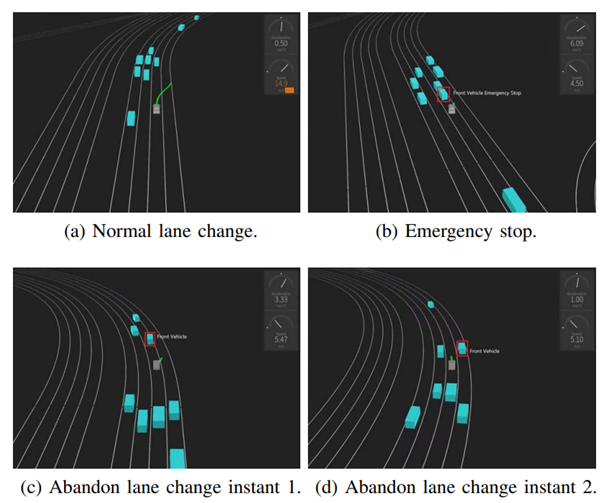
图5 场景测试
[返回]
![第五篇:Yang X, Qian Y, Zhu H, et al. BAANet: Learning Bi-directional Adaptive Attention Gates for Multispectral Pedestrian Detection[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 2920-2926.](/__local/D/53/3A/7D21A50B38700735E43239BBBA6_7D2B1C04_26B5.png)

➢ 研究背景与意义
该工作主要是多光谱的行人检测任务。由于可见光相机容易受到光照的影响,从而导致障碍物的漏检,给道路交通安全带来威胁。而热红外(Thermal Infrared,简称TIR)相机,通过捕捉物体所散发出的温度信息,如行人所辐射的波长为9.3µm的电磁波,能够在无需外部的主动光源的情况下便可以探测到障碍物物体。


(a) (b)
图1:图(a)是可见光相机拍摄的图像,图(b)是热红外相机拍摄的图像
但是,由于可见光相机和红外相机捕捉的是不同维度的信息,因此,他们之间的融合仍然存在问题,主要体现在对于在不同的光照条件下的不同的模态,可见光模态和红外模态均存在单个模态中的噪声影响融合效果的情况。

图2:RGB和TIR模态中存在的噪声情况
➢ 本文工作
本文提出了双向自适应注意力门(Bi-directional Adaptive Attention Gates,检测BAA-Gate),其结构如下图所示。
通过在可见光和红外图像障碍物检测算法的两个特征提取支流之间,插入双向自适应注意力门模块,分别从特征的通道和空间两个层面,去除了每个模态中的冗余噪声,并通过基于光照加权的模态交互,进一步完备了各个模态的特征质量,从而提高检测效果。
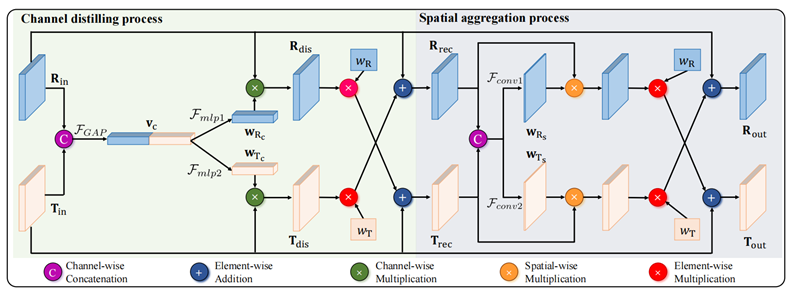
图3:BAA-Gate网络结构
➢ 实验结果
本方法在于其他方法对比中取得sota效果,如下分别展示了定性实验结果和定量实验结果,其中在夜晚场景下较其他方法提升效果明显。

图5:定性实验结果对比
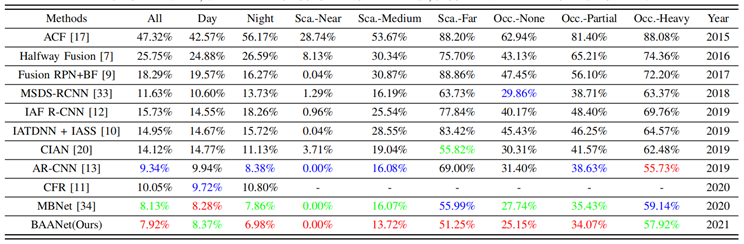
图6:定量实验结果对比
[返回]